staticvoidMakeBreakfast() { var cup = PourCoffee(); Console.WriteLine("coffee is ready");
var eggs = FryEggs(2); Console.WriteLine("eggs are ready");
var bacon = FryBacon(3); Console.WriteLine("bacon is ready");
var toast = ToastBread(2); ApplyButter(toast); ApplyJam(toast); Console.WriteLine("toast is ready");
var oj = PourOJ(); Console.WriteLine("oj is ready"); Console.WriteLine("Breakfast is ready!"); }
static Juice PourOJ() { Console.WriteLine("Pouring orange juice"); returnnew Juice(); }
staticvoidApplyJam(Toast toast) => Console.WriteLine("Putting jam on the toast");
staticvoidApplyButter(Toast toast) => Console.WriteLine("Putting butter on the toast");
static Toast ToastBread(int slices) { for (int slice = 0; slice < slices; slice++) { Console.WriteLine("Putting a slice of bread in the toaster"); } Console.WriteLine("Start toasting..."); Task.Delay(3000).Wait(); Console.WriteLine("Remove toast from toaster"); returnnew Toast(); }
static Bacon FryBacon(int slices) { Console.WriteLine($"putting {slices} slices of bacon in the pan"); Console.WriteLine("cooking first side of bacon..."); Task.Delay(3000).Wait(); for (int slice = 0; slice < slices; slice++) { Console.WriteLine("flipping a slice of bacon"); } Console.WriteLine("cooking the second side of bacon..."); Task.Delay(3000).Wait(); Console.WriteLine("Put bacon on plate"); returnnew Bacon(); }
static Egg FryEggs(int howMany) { Console.WriteLine("Warming the egg pan..."); Task.Delay(3000).Wait(); Console.WriteLine($"cracking {howMany} eggs"); Console.WriteLine("cooking the eggs ..."); Task.Delay(3000).Wait(); Console.WriteLine("Put eggs on plate"); returnnew Egg(); }
staticasync Task MakeBreakfastAsync() { var cup = PourCoffee(); Console.WriteLine("coffee is ready");
var eggs = await FryEggsAsync(2); Console.WriteLine("eggs are ready");
var bacon = await FryBaconAsync(3); Console.WriteLine("bacon is ready");
var toast = await ToastBreadAsync(2); ApplyButter(toast); ApplyJam(toast); Console.WriteLine("toast is ready");
var oj = PourOJ(); Console.WriteLine("oj is ready"); Console.WriteLine("Breakfast is ready!"); }
staticasync Task<Toast> ToastBreadAsync(int slices) { for (int slice = 0; slice < slices; slice++) { Console.WriteLine("Putting a slice of bread in the toaster"); } Console.WriteLine("Start toasting..."); Task.Delay(3000).Wait(); Console.WriteLine("Remove toast from toaster"); returnawait Task.FromResult(new Toast()); }
static Task<Bacon> FryBaconAsync(int slices) { Console.WriteLine($"putting {slices} slices of bacon in the pan"); Console.WriteLine("cooking first side of bacon..."); Task.Delay(3000).Wait(); for (int slice = 0; slice < slices; slice++) { Console.WriteLine("flipping a slice of bacon"); } Console.WriteLine("cooking the second side of bacon..."); Task.Delay(3000).Wait(); Console.WriteLine("Put bacon on plate"); return Task.FromResult(new Bacon()); }
static Task<Egg> FryEggsAsync(int howMany) { Console.WriteLine("Warming the egg pan..."); Task.Delay(3000).Wait(); Console.WriteLine($"cracking {howMany} eggs"); Console.WriteLine("cooking the eggs ..."); Task.Delay(3000).Wait(); Console.WriteLine("Put eggs on plate"); return Task.FromResult(new Egg()); }
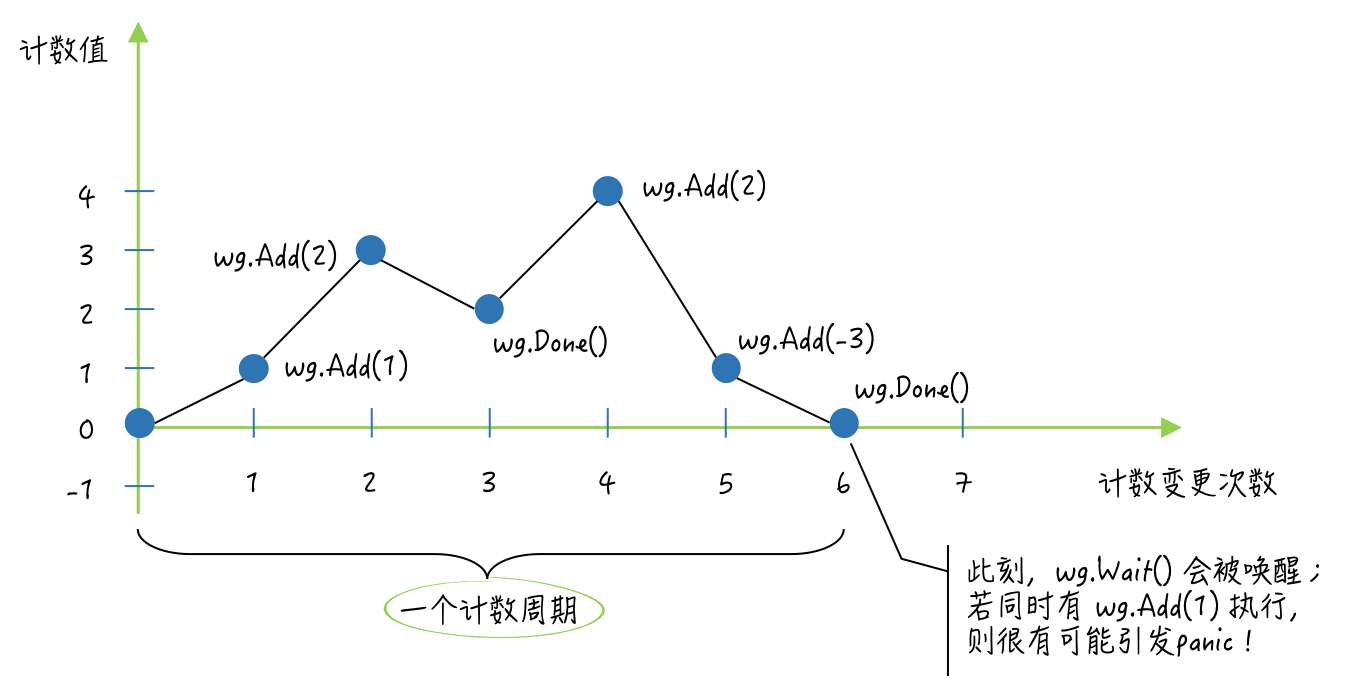
funccoordinateWithWaitGroup() { total := 12 stride := 3 var num int32 fmt.Printf("The number: %d [with sync.WaitGroup]\n", num) var wg sync.WaitGroup for i := 1; i <= total; i = i + stride { wg.Add(stride) for j := 0; j < stride; j++ { go addNum(&num, i+j, wg.Done) } wg.Wait() } fmt.Println("End.") }
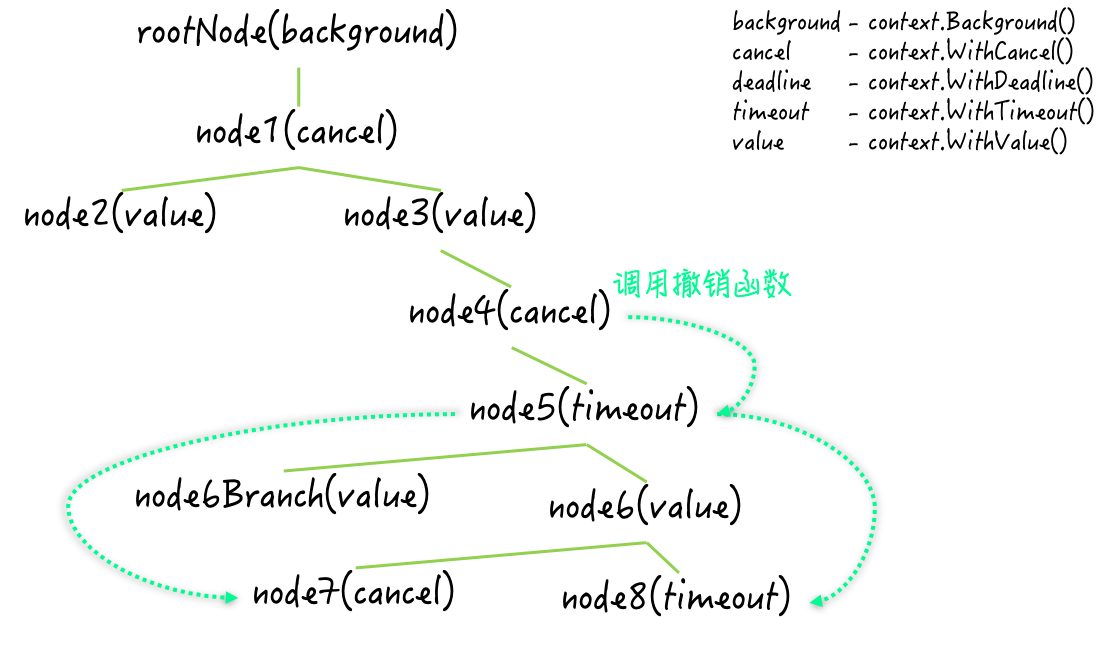
funccoordinateWithContext() { total := 12 var num int32 fmt.Printf("The number: %d [with context.Context]\n", num) cxt, cancelFunc := context.WithCancel(context.Background()) for i := 1; i <= total; i++ { go addNum(&num, i, func() { if atomic.LoadInt32(&num) == int32(total) { cancelFunc() } }) } <-cxt.Done() fmt.Println("End.") }
]]>
Go语言核心36讲-context.Context类型2026-04-13T10:24:15.849Zcaty
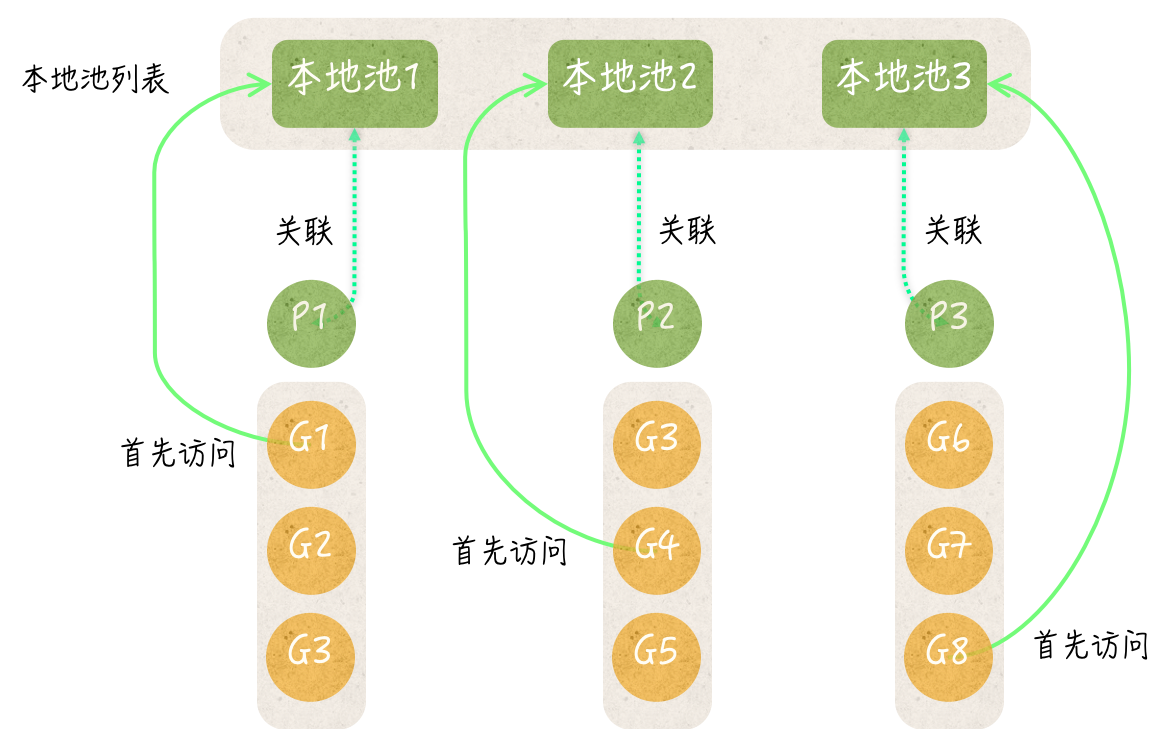
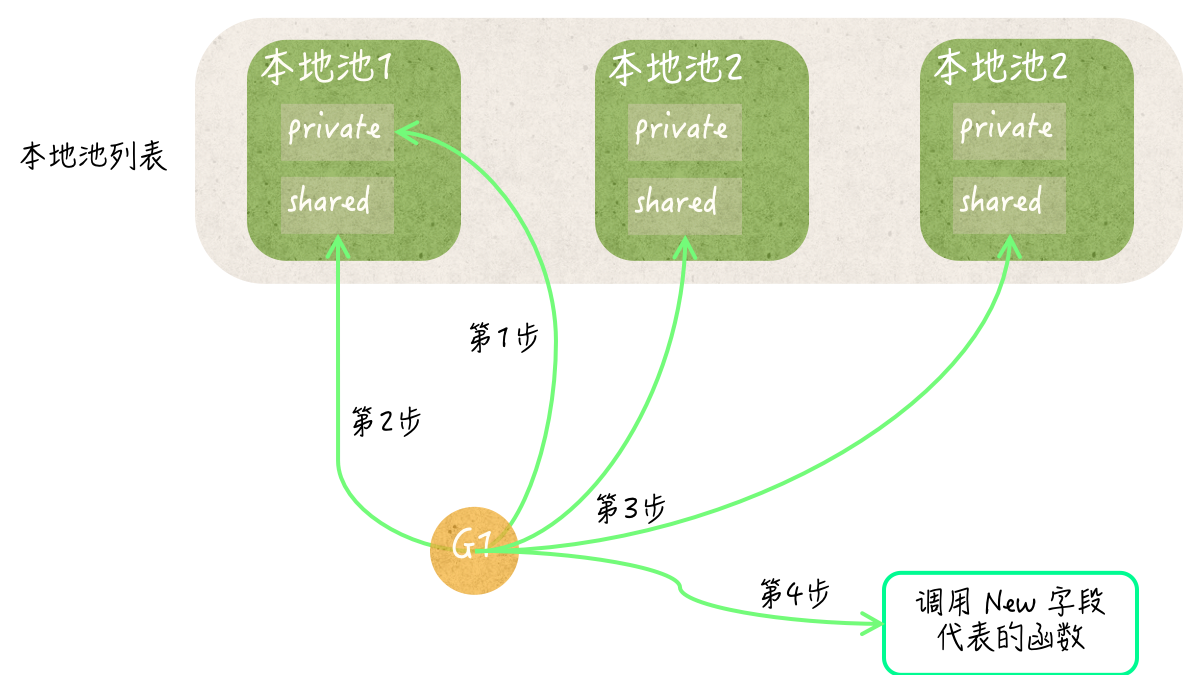
sync.Pool类型可以被称为临时对象池,它的值可以被用来存储临时的对象。与 Go 语言的很多同步工具一样,sync.Pool类型也属于结构体类型,它的值在被真正使用之后,就不应该再被复制了。
]]>
http://blog.chcaty.cn/2021/11/29/go-yu-yan-he-xin-36-jiang-lin-shi-dui-xiang-chi-sync.pool/2021-11-29T15:43:58.000Z
sync.Pool类型可以被称为临时对象池,它的值可以被用来存储临时的对象。与 Go 语言的很多同步工具一样,sync.Pool类型也属于结构体类型,它的值在被真正使用之后,就不应该再被复制了。
funccoordinateWithWaitGroup() { var wg sync.WaitGroup wg.Add(2) num := int32(0) fmt.Printf("The number: %d [with sync.WaitGroup]\n", num) max := int32(10) go addNum(&num, 3, max, wg.Done) go addNum(&num, 4, max, wg.Done) wg.Wait() }
goroutine 1 [running]: main.main() /Users/haolin/GeekTime/Golang_Puzzlers/src/puzzlers/article19/q0/demo47.go:5 +0x3d exit status 2
这份详情的第一行是“panic: runtime error: index out of range”。其中的“runtime error”的含义是,这是一个runtime代码包中抛出的 panic。在这个 panic 中,包含了一个runtime.Error接口类型的值。runtime.Error接口内嵌了error接口,并做了一点点扩展,runtime包中有不少它的实现类型。
]]>
http://blog.chcaty.cn/2021/11/25/go-yu-yan-he-xin-36-jiang-panic-han-shu-recover-han-shu-yi-ji-defer-yu-ju-shang/2021-11-25T15:43:58.000Z
Go 语言的另外一种错误处理方式,不过,严格来说,它处理的不是错误,而是一场,并且时一种在我们意料之外的程序异常。]]>
Go语言核心36讲-panic函数、recover函数以及defer语句(上)2026-04-13T10:24:15.850Zcaty
error类型其实是一个接口类型,也是一个 Go 语言的内建类型。在这个接口类型的声明中只包含了一个方法Error。Error方法不接受任何参数,但是会返回一个string类型的结果。它的作用是返回错误信息的字符串表示形式。
]]>
http://blog.chcaty.cn/2021/11/23/go-yu-yan-he-xin-36-jiang-sync.mutex-yu-sync.rwmutex/2021-11-23T15:43:58.000Z
从本篇文章开始,我们将一起探讨 Go 语言自带标准库中一些比较核心的代码包。这会涉及这些代码包的标准用法、使用禁忌、背后原理以及周边的知识。]]>
Go语言核心36讲-sync.Mutex与sync.RWMutex2026-04-13T10:24:15.850Zcaty
在本篇文章,我会继续为你讲解更多更高级的测试方法。这会涉及testing包中更多的 API、go test命令支持的,更多标记更加复杂的测试结果,以及测试覆盖度分析等等。
前导内容:-cpu 的功能
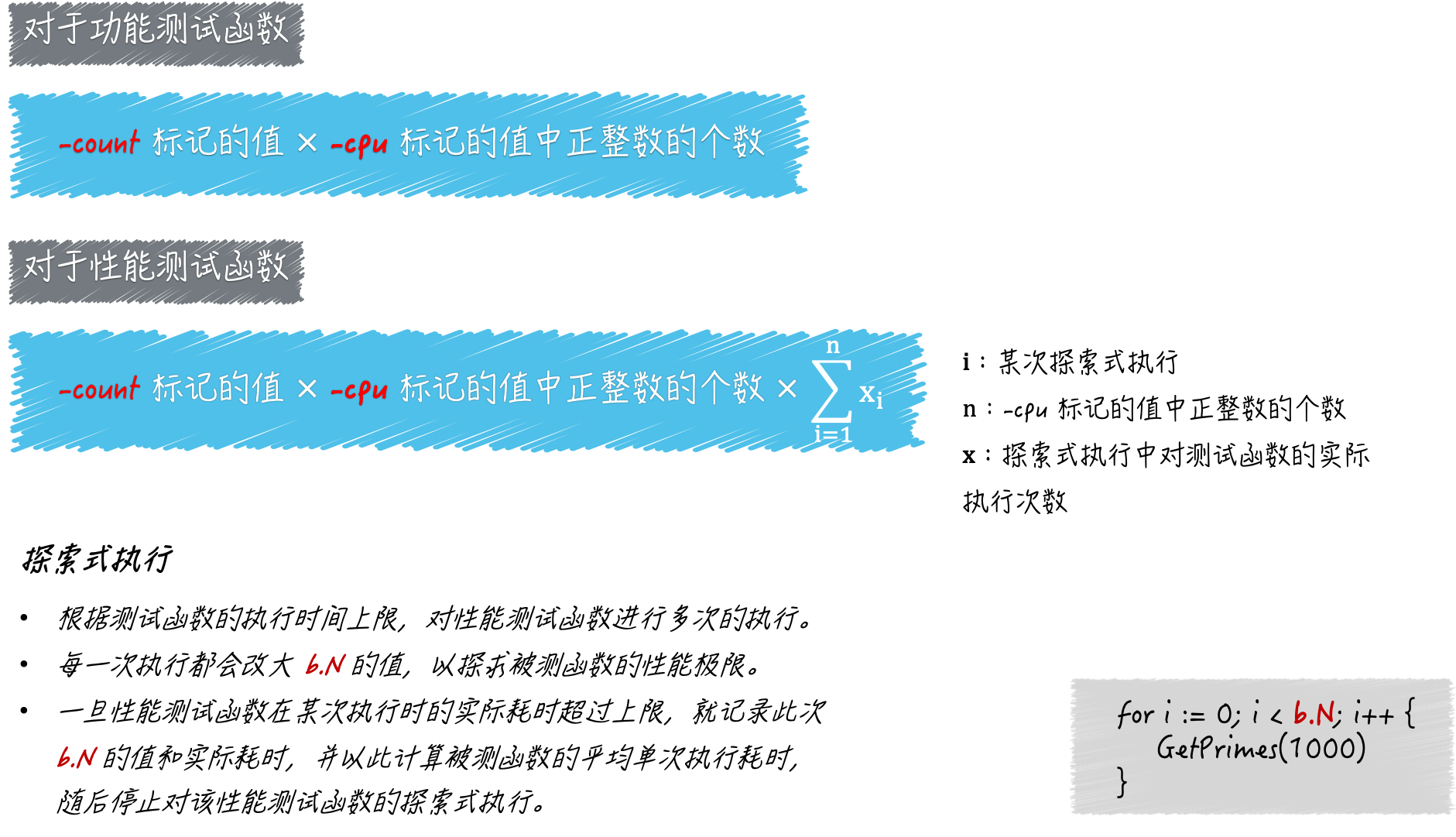
go test命令的标记-cpu,它是用来设置测试执行最大 P 数量的列表的。
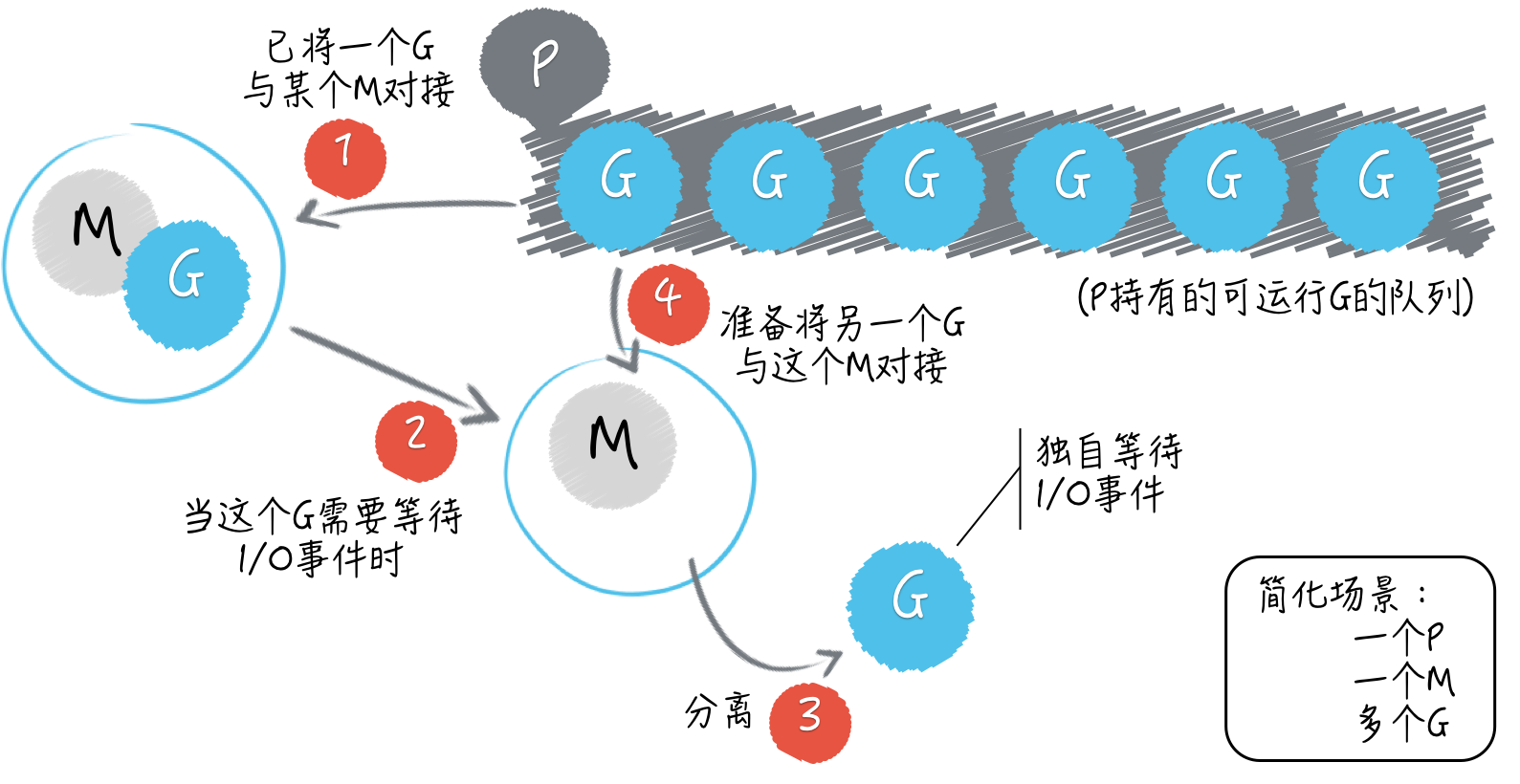
这里的 P 是 processor 的缩写,每个 processor 都是一个可以承载若干个 G,且能够使这些 G 适时地与 M 进行对接并得到真正运行的中介。 正是由于 P 的存在,G 和 M 才可以呈现出多对多的关系,并能够及时、灵活地进行组合和分离。 这里的 G 就是 goroutine 的缩写,可以被理解为 Go 语言自己实现的用户级线程。M 即为 machine 的缩写,代表着系统级线程,或者说操作系统内核级别的线程。
Go 语言并发编程模型中的 P,正是 goroutine 的数量能够数十万计的关键所在。P 的数量意味着 Go 程序背后的运行时系统中,会有多少个用于承载可运行的 G 的队列存在。
每一个队列都相当于一条流水线,它会源源不断地把可运行的 G 输送给空闲的 M,并使这两者对接。
一旦对接完成,被对接的 G 就真正地运行在操作系统的内核级线程之上了。每条流水线之间虽然会有联系,但都是独立运作的。
因此,最大 P 数量就代表着 Go 语言运行时系统同时运行 goroutine 的能力,也可以被视为其中逻辑 CPU 的最大个数。而go test命令的-cpu标记正是用于设置这个最大个数的。
$ go test -bench=. -run=^$ puzzlers/article20/q3 goos: darwin goarch: amd64 pkg: puzzlers/article20/q3 BenchmarkGetPrimes-85000002314 ns/op PASS ok puzzlers/article20/q3 1.192s
我在运行go test命令的时候加了两个标记。第一个标记及其值为-bench=.,只有有了这个标记,命令才会进行性能测试。该标记的值.表明需要执行任意名称的性能测试函数,当然了,函数名称还是要符合 Go 程序测试的基本规则的。
numbers2 := [...]int{1, 2, 3, 4, 5, 6} maxIndex2 := len(numbers2) - 1 for i, e := range numbers2 { if i == maxIndex2 { numbers2[0] += e } else { numbers2[i+1] += e } } fmt.Println(numbers2)
value1 := [...]int8{0, 1, 2, 3, 4, 5, 6} switch1 + 3 { case value1[0], value1[1]: fmt.Println("0 or 1") case value1[2], value1[3]: fmt.Println("2 or 3") case value1[4], value1[5], value1[6]: fmt.Println("4 or 5 or 6") }
value5 := [...]int8{0, 1, 2, 3, 4, 5, 6} switch value5[4] { case value5[0], value5[1], value5[2]: fmt.Println("0 or 1 or 2") case value5[2], value5[3], value5[4]: fmt.Println("2 or 3 or 4") case value5[4], value5[5], value5[6]: fmt.Println("4 or 5 or 6") }